

Scraping the web can be a good way to acquire on-page HTML data, which can be used to create insightful infographics or for custom applications. One of the most powerful tools to achieve this is the Beautiful Soup library within Python It is specifically built to allow users to scrape all forms of data from any webpage on the internet.
As such, in this tutorial, we’ll be looking at how to scrape YouTube title and views as an example. But, this method can be applied to any webpage with meta-data. Why meta-data? Because it is the most consistent way of storing information about a page’s title, views, likes, and so on. Due to it being external from YouTube, it’s essentially unaffected by source code changes.
A common problem with targeting HTML elements such as classes, IDs, or even containers themselves is that they can change drastically when the source code is updated. This is what has happened with the new YouTube source code, completely overhauling its class names and causing old methods to not function as well.
Where do we start?
To get the title and view data from a handful of Christmas adverts on Youtube, we started by defining an array of URLs, delimited by commas and formatted in strings.
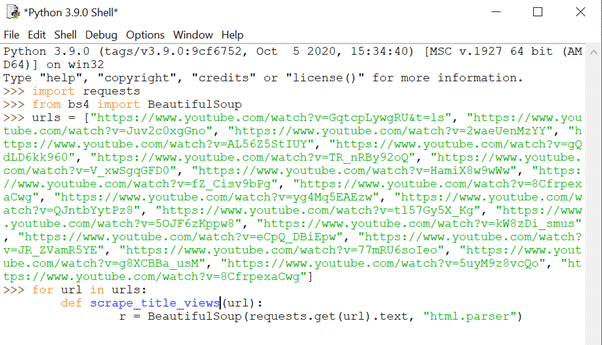
Then, using the statement ‘for url in urls’, we targeted each individual URL from the array to define our function.
Using the define (‘def’) keyword, we named our function ‘scrape_title_views’, with the parameter of ‘(url)’, which allowed us to run the function for each URL later-on.
The next step is to specify a variable going by the letter ‘r’, in which we assigned a built-in HTML parser to scrape the entire URL for text in its HTML content.
Note: HTML parser is not the fastest parser, and certainly for larger web scraping tasks there are better ones available, but it will do the job well for smaller tasks such as this.

Following this, we needed to define a few other variables before getting our function to fetch the data we want, including ‘title’, ‘views’, and finally ‘data’.
Starting with ‘title’: We are using dot notation to access our ‘r’ variable, since this contains all the parsed HTML content from which we can extract the pieces of information we need. As we only need to find one title in the page, the ‘select_one()’ command will suffice. Within the parentheses, we accessed the meta data of the page – specifically the itemprop Schema attribute which contains name-value pairs like ‘title: [title of YouTube video]’. For this title variable, we’re fetching the ‘name’ property.
Our ‘views’ variable follows the exact same format, except that we’re fetching the ‘interactionCount’ property instead.
Finally, our ‘data’ variable enabled us to store our title and views data in a specified format within the curly braces, such as: ‘{‘title’:title, ‘views’:views}’. The format can be whichever style you prefer, like: ‘{title, views}’.
To end our function, we put our return statement, which is to return data for each time our function iterates through each URL in the ‘urls’ array.
Our function is now ready to be called. Because we want to be able to reuse this function multiple times, we kept it separate so that we can modify it as we please, without having to constantly re-write it for different tasks. This would be important if you want to print all the titles together, and then all the views together, as in the screenshot below:
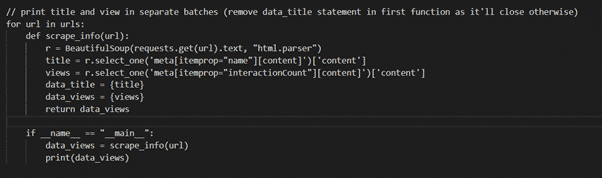
Instead of writing two separate statements for the titles and views, we simply need to switch the return statement for whichever we want to fetch (remember that we can only specify one return statement because the function closes immediately after the first).
Going back to our initial example where we print the title and view count together, we needed to call the function.

In our ‘if’ statement, we simply stated that if the name (‘__name__’) of our module is the one we are currently using (‘__main__’), then the Python interpreter needs to run the if statement. It is best practice to use this for ‘if’ statements within Python.
Within this statement, we called the ‘data’ variable, and we’re telling the interpreter to fill it with the information that we’ve specified in the ‘scrape_title_views(url)’ function. So in this case, we’re fetching the title and views, and assigning them to the ‘data’ variable in the format we stated it should be in (which is: ‘{‘title’:title, ‘views’:views}’).
To finish, we instructed the interpreter to print out the ‘data’ variable, which will execute once you press ‘enter’ twice to exit out of the statement. Below you can see that the interpreter has successfully retrieved and printed the data we were looking for:
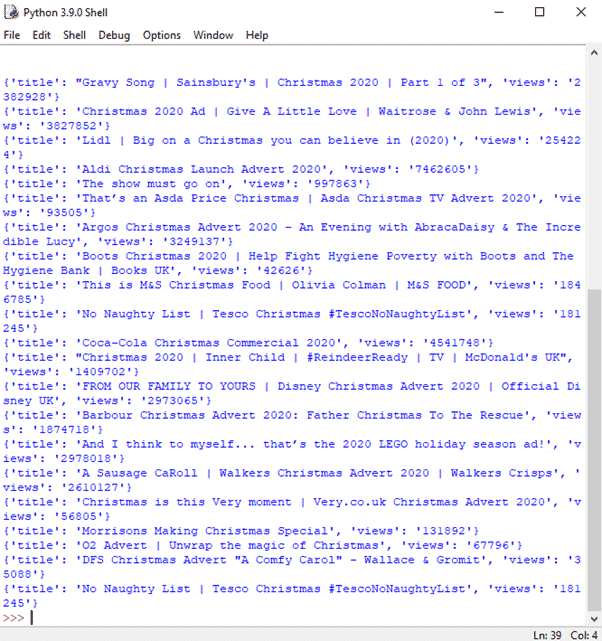
But a long list of letters and numbers will leave you feeling as blue as the text, so be sure to convert this data into something visually appealing with libraries like ChartJS. We’ve done exactly this by creating a Christmas-themed graph showcasing YouTube views. Take a look here >
If you’d like help collecting or analysing data to create interesting graphs, charts or infographics get in touch with us >